
티스토리 뷰
트랜잭션의 격리 수준(isolation level)
여러 트랜잭션이 동시에 처리될 때 특정 트랜잭션이 다른 트랜잭션에서 변경하거나 조회하는 데이터를 볼 수 있게 허용할지 말지를 결정하는 것
| 격리 수준 | Dirty Read | Non-Repleatable Read | Phantom Read |
| READ UNCOMMITTED | 발생 | 발생 | 발생 |
| READ COMMITTED | 없음 | 발생 | 발생 |
| REPEATABLE READ | 없음 | 없음 | 발생 (innoDB는 없음) |
| SERIALIZABLE | 없음 | 없음 | 없음 |
4개의 격리 수준에서 순서대로 뒤로 갈수록 각 트랜잭션 간의 데이터 격리(고립) 정도가 높아지며, 동시 처리 성능도 떨어지는 것이 일반적이다. 격리 수준이 높아질수록 MySQL 서버의 처리 성능이 많이 떨어질 것으로 생각하는 사용자가 많은데, 사실 SERIALIZABLE 격리 수준이 아니라면 크게 성능의 개선이나 저하는 발생하지 않는다.
일반적인 온라인 서비스 용도의 데이터베이스는 READ COMMITTED와 REPEATABLE READ 중 하나를 사용한다.
ex) ORACLE - READ COMMITTED , MYSQL - REPEATABLE READ
1.READ UNCOMMITTED
READ UNCOMMITTED 격리 수준에서는 각 트랜잭션에서의 변경 내용이 COMMIT이나 ROLLBACK 여부에 상관없이 다른 트랜잭션에서 보인다.
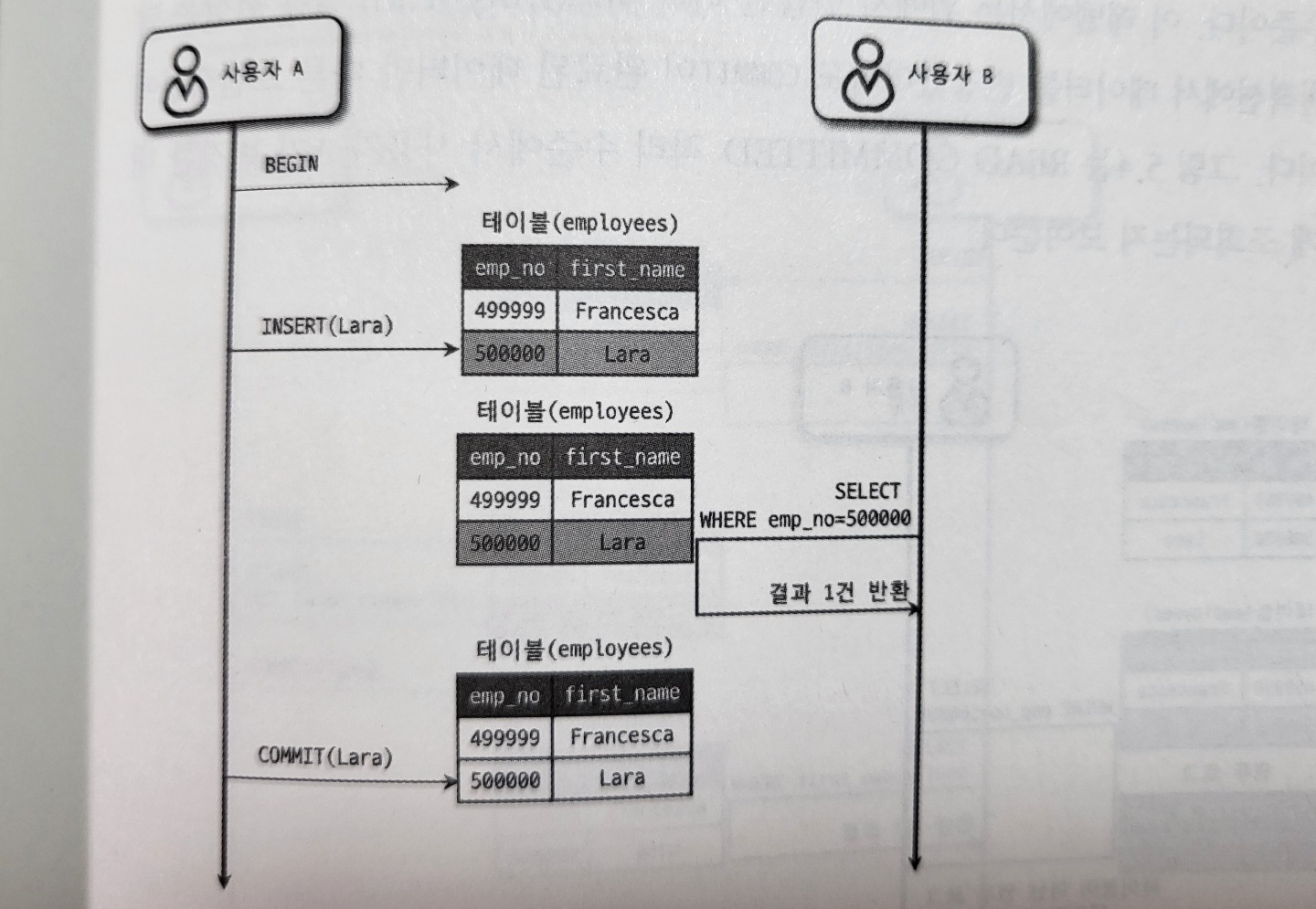
사용자 B는 사용자 A가 INSERT 한 사원의 정보(eml_no = 500000)를 커밋되지 않은 상태에서도 조회할 수 있다.
문제는 사용자 A가 처리 도중 알 수 없는 문제가 발생해 INSERT 된 내용을 롤백한다고 하더라도 여전히 사용자 B는 'Lara'가 정상적인 사원이라고 생각하고 계속 처리할 것이다.
이처럼 어떤 트랜잭션에서 처리한 작업이 완료되지 않았는데도 다른 트랜잭션에서 볼 수 있는 현상을 더티 리드(Dirty Read)라 하고, 더티 리드가 허용되는 격리 수준이 READ UNCOMMITTED다. 더티 리드 현상은 데이터가 나타났다가 사라졌다 하는 현상을 초래하므로 애플리케이션 개발자와 사용자를 상당히 혼란스럽게 만든다.
2.READ COMMITTED
READ COMMITTED는 오라클 DBMS에서 기본으로 사용되는 격리 수준이며, 온라인 서비스에서 가장 많이 선택되는 격리 수준이다. 이 레벨에서는 위에서 언급한 더티 리드(Dirty read) 같은 현상은 발생하지 않는다. 어떤 트랜잭션에서 데이터를 변경했더라도 COMMIT이 완료된 데이터만 다른 트랜잭션에서 조회할 수 있기 때문이다.

사용자 A는 emp_no = 500000인 사원의 first_name을 'Lara'에서 'Toto'로 변경했는데, 이때 새로운 값인 'Toto'는 employees 테이블에 즉시 기록되고 이전 값인 'Lara'는 언두 영역으로 백업된다. 이로인해 사용자 A가 커밋을 수행하기 전에 사용자 B가 emp_no = 500000인 사원을 조회하면 'Toto'가 아니라 'Lara'가 조회된다. 사용자 B의 쿼리 결과는 employees 테이블이 아니라 언두 영역에 백업된 레코드에서 가져온 것이다.
READ COMMITTED 격리 수준에서는 어떤 트랜잭션에서 변경한 내용이 커밋되기 전까지는 다른 트랜잭션에서 그러한 변경 내역을 조회할 수 없다. 최종적으로 사용자 A가 변경된 내용을 커밋하면 그때부터는 다른 트랜잭션에서도 백업된 언두 레코드('Lara')가 아니라 새롭게 변경된 'Toto'라는 값을 참조할 수 있게 된다.
READ COMMITTED 격리 수준에서도 'NON-REPEATABLE READ(REPEATABLE READ가 불가능하다) 라는 부정합의 문제가 있다.

사용자 B가 BEGIN 명령으로 트랜잭션을 시작하고 first_name이 'Toto'인 사용자를 검색했는데, 일치하는 결과가 없었다. 하지만 사용자 A가 사원 번호가 500000인 사원의 이름을 'Toto'로 변경하고 커밋을 실행한 후 , 사용자 B가 똑같은 SELECT 쿼리로 다시 조회하면 이번에는 결과가 1건이 조회된다.
이는 별다른 문제가 없어 보이지만, 사실 사용자 B가 하나의 트랜잭션 내에서 똑같은 SELECT 쿼리를 실행했을 때는 항상 같은 결과를 가져와야 한다는 'REPETABLE READ' 정합성에 어긋나는 것이다.
이러한 부정합 현상은 일반적인 웹 프로그램에서는 크게 문제되지 않을 수 있지만 하나의 트랜잭션에서 동일 데이터를 여러 번 읽고 변경하는 작업이 금전적인 처리와 연결되면 문제가 될 수 있다.
예를 들어, 어떤 트랜잭션에서 입금과 출금 처리가 계속 진행될 때 다른 트랜잭션에서 오늘 입금된 금액의 총합을 조회한다고 가정해보자.
'REPEATABLE READ'가 보장되지 않기 때문에 총합을 계산하는 SELECT 쿼리는 실행될 때마다 다른 결과를 가져올 것이다.
중요한 것은 사용중인 트랜잭션의 격리 수준에 의해 실행하는 SQL 문장이 어떤 결과를 가져오게 되는지를 정확히 예측할 수 있어야 한다는 것이다. 그리고 당연히 이를 위해서는 각 트랜잭션의 격리 수준이 어떻게 작동하는지 알아야 한다.
가끔 사용자 중에서 트랜잭션 내에서 실행되는 SELECT 문장과 트랜잭션 없이 실행되는 SELECT 문장의 차이를 혼동하는 경우가 있다. READ COMMITTED 격리 수준에서는 트랜잭션 내에서 실행되는 SELECT 문장과 트랜잭션 외부에서 실행되는 SELECT 문장의 차이가 별로 없다.
하지만 REPEATABLE READ 격리 수준에서는 기본적으로 SELECT 쿼리 문장도 트랜잭션 범위 내에서만 작동한다. 즉 START TRANSACTION(또는 BEGIN) 명령으로 트랜잭션을 시작한 상태에서 온종일 동일한 쿼리를 반복해서 실행해봐도 동일한 결과만 보게 된다.(아무리 다른 트랜잭션에서 그 데이터를 변경하고 COMMIT을 실행한다고 하더라도 말이다). 별로 중요하지 않은 차이처럼 보이지만 이런 문제로 데이터의 정합성이 깨지고 그로 인해 애플리케이션에 버그가 발생하면 찾아내기가 쉽지 않다.
3.REPEATABLE READ
REPEATABLE READ는 MySQL의 InnoDB 스토리지 엔진에서 기본으로 사용되는 격리 수준이다. 이 격리 수준에서는 READ COMMITTED 격리 수준에서 발생하는 'NON-REPEATABLE READ' 부정합이 발생하지 않는다.
InnoDB 스토리지 엔진은 트랜잭션이 ROLLBACK될 가능성에 대비해 변경되기 전 레코드를 언두(Undo) 공간에 백업해두고 실제 레코드 값을 변경한다. 이러한 방식을 MVCC(Multi Version Concurrency Control)이라고 한다. REPEATABLE READ는 이 MVCC를 위해 언두 영역에 백업된 이전 데이터를 이용해 동일 트랜잭션 내에서는 동일한 결과를 보여줄 수 있게 보장한다.
사실 READ COMMITTED도 MVCC를 이용해 COMMIT되기 전의 데이터를 보여준다. REPEATABLE READ와 READ COMMITTED의 차이는 언두 영역에 백업된 레코드의 여러 버전 가운데 몇 번째 이전 버전까지 찾아 들어가야 하느냐에 있다.
모든 InnoDB의 트랜잭션은 고유한 트랜잭션 번호(순차적으로 증가하는 값)를 가지며, 언두 영역에 백업된 모든 레코드에는 변경을 발생시킨 트랜잭션의 번호가 포함돼 있다. REPEATABLE READ 격리 수준에서는 MVCC를 보장하기 위해 실행 중인 트랜잭션 가운데 가장 오래된 트랜잭션 번호보다 트랜잭션 번호가 앞선 언두 영역의 데이터는 삭제할 수 없다.

사용자 B의 트랜잭션의 번호는 10이다. 사용자 B가 BEGIN 명령으로 트랜잭션을 시작하면서 10번이라는 트랜잭션 번호를 부여받았고, 그때부터 사용자 B의 10번 트랜잭션 안에서 실행되는 모든 SELECT 쿼리는 트랜잭션 번호가 10(자신의 트랜잭션 번호) 보다 작은 트랜잭션 번호에서 변경한 것만 보게 된다.
그림에서는 언두 영역에 백업된 데이터가 하나만 있는 것으로 표현했지만 사실 하나의 레코드에 대해 백업이 하나 이상 얼마든지 존재할 수 있다. 한 사용자가 BEGIN으로 트랜잭션을 시작하고 장시간 트랜잭션을 종료하지 않으면 언두 영역이 백업된 데이터로 무한정 커질 수도 있다. 이렇게 언두에 백업된 레코드가 많아지면 MySQL 서버의 처리 성능이 떨어질 수 있다.
REPEATABLE READ 격리 수준에서도 다음과 같은 부정합이 발생할 수 있다. 아래는 사용자 A가 employees 테이블에 INSERT를 실행하는 도중에 사용자 B가 SELECT... FOR UPDATE 쿼리로 employees 테이블을 조회했을 때 결과를 보여준다.
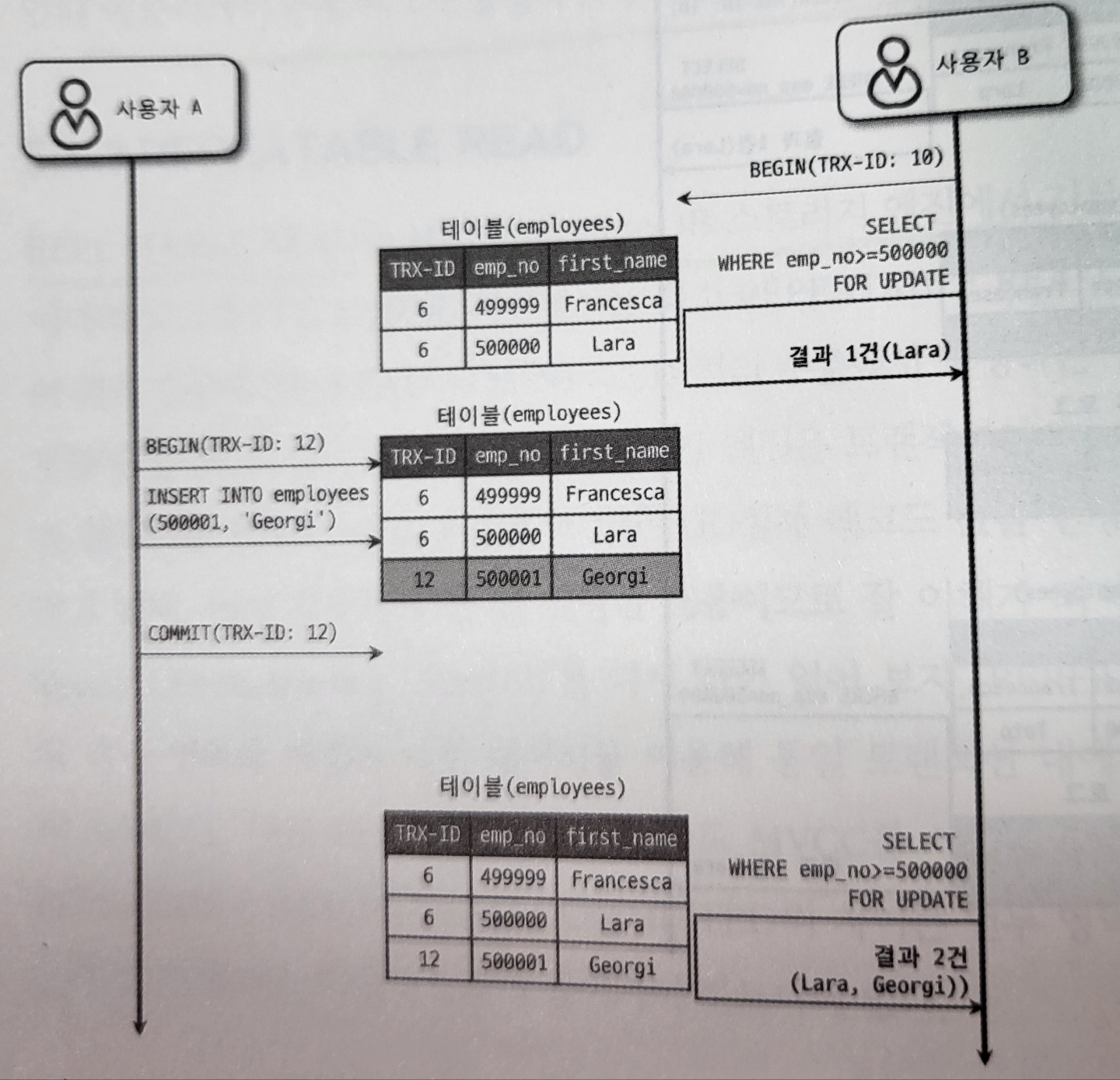
이렇게 다른 트랜잭션에서 수행한 변경 작업에 의해 레코드가 보였다 안 보였다 하는 현상을 PHANTOM READ(또는 PHANTOM ROW)라고 한다.
SELECT .. FOR UPDATE 쿼리는 SELECT 하는 레코드에 쓰기 잠금을 걸어야 하는데, 언두 레코드에는 잠금을 걸 수 없다. 그래서 SELECT... FOR UPDATE나 LOCK IN SHARE MODE로 조회되는 레코드는 언두 영역의 변경 전 데이터를 가져오는 것이 아니라 현재 레코드의 값을 가져오게 되는 것이다.
4.SERIALIZABLE
가장 단순한 격리 수준이면서 동시에 가장 엄격한 격리 수준이다. 그만큼 동시 처리 성능도 다른 트랜잭션 격리 수준보다 떨어진다.
InnoDB 테이블에서 기본적으로 순수한 SELECT 작업 (INSERT ... SELECT .. 또는 CREATE TABLE ... AS SELECT .. 가 아닌) 은 아무런 레코드 잠금도 설정하지 않고 실행된다.
하지만 트랜잭션의 격리 수준이 SERIALIZABLE로 설정되면 읽기 작업도 공유 잠금(읽기 잠금)을 획득해야만 하며, 동시에 다른 트랜잭션은 그러한 레코드를 변경하지 못하게 된다. 즉, 한 트랜잭션에서 읽고 쓰는 레코드를 다른 트랜잭션에서는 절대 접근할 수 없는 것이다.
SERIALIZABLE 격리 수준에서는 일반적인 DBMS에서 일어나는 'PHANTOM READ' 라는 문제가 발생하지 않는다. 하지만 InnoDB 스토리지 엔진에서는 갭 락과 넥스트 키 락 덕분에 REPEATABLE READ 격리 수준에서도 이미 'PHANTOM READ'가 발생하지 않기 때문에 굳이 SERIALIZABLE을 사용할 필요성은 없어 보인다.
출처
Real MySQL 8.0 1권
http://www.kyobobook.co.kr/product/detailViewKor.laf?mallGb=KOR&ejkGb=KOR&barcode=2909101309302
Real MySQL 8.0 세트(1권 2권 구성)(전면개정판) - 교보문고
개발자와 DBA를 위한 MySQL 실전 가이드 | MySQL 서버를 활용하는 프로젝트에 꼭 필요한 경험과 지식을 담았습니다!《Real MySQL 8.0》은 《Real MySQL》을 정제해서 꼭 필요한 내용으로 압축하고, MySQL 8.0
www.kyobobook.co.kr
'DB > RDB' 카테고리의 다른 글
| [ORACLE] multiple row update (0) | 2019.10.24 |
|---|---|
| mybatis invalid comparison: java.util.ArrayList and java.lang.String (0) | 2019.08.16 |
| [MS-SQL] Begin Tran (0) | 2019.06.13 |
| [MSSQL] multiple row update (0) | 2019.05.28 |
| [MSSQL] 다른 데이터베이스 데이터 복사 (0) | 2019.05.17 |
- Total
- Today
- Yesterday
- java
- 슬랙
- visual studio code
- 뱅크샐러드
- spring-boot-starter-data-redis
- gradle
- 뱅크샐러드 유전자
- MSSQL
- springboot https
- update query
- 뱅셀 유전자
- Slack
- 다중 업데이트
- 몽고DB 완벽가이드
- update query set multiple
- update query multi row
- 업데이트 쿼리
- 슬랙봇
- update query mutiple row
- 슬랙 /
- 이펙티브자바
- 이것이 자바다
- effectivejava
- update set multi
- update set multiple
- SpringBoot
- 그레이들
- multiple row update
- 싱글턴
- vue.js
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |